
ChatGPT, an ethical analysis

With the free user version of OpenAI, ChatGPT has reached a large audience and introduced many people to the possibilities of so-called generative AI since November 2022. ChatGPT is a Large Language Model (LLM), which is a form of artificial intelligence that is able to generate new text output based on existing data sets and Machine Learning algorithms. Other parties, such as Google (Bard) and Meta (LlaMA), have developed comparable commercial LLMs in addition to OpenAI’s ChatGPT. Moreover, in March of this year Microsoft announced Copilot, which is a new feature that uses the models of OpenAI to integrate AI in all Microsoft 365 services.[i]
As stated above, ChatGPT generates text, while other forms of generative AI can also generate videos, illustrations and speech (examples are DALL-E and Midjourney). ChatGPT is available free of charge, and many people try it out at least once.
We would like to raise attention to the ethical issues that the use of ChatGPT and other LLMs raises, which will follow below.
Technical aspects
Before identifying the ethical aspects of using LLMs, we are first giving a brief technical explanation as to how LLMs work, about the possibilities of application and the first ethical issues that this entails.
Operation of LLMs
How do Large Language Models operate? Let’s start with the ‘backend’: LLMs have been trained using extensive data sets that use ‘public’ sources on a large scale.[ii] That means text that is freely accessible on the Internet, but has not necessarily been ‘released’ (but has rather been obtained through web scraping, among other things). ChatGPT is an LLM. GPT stands for Generative Pretrained Transformer: This system can process large quantities of text and recognises patterns in language. It can subsequently calculate which words could logically follow, and construct complex argumentations. You can compare it to an autocorrection system:[iii] that adjusts your words or suggests another word or spelling. LLMs are able to do this in a more predictive manner of what might potentially follow after another word and in larger sequences, and they are also able to create a correlation between several parts of a text and argumentations. Many LLMs, including ChatGPT, use Reinforcement Learning on Human Feedback (RLHF). This means that people adjust the model by pointing out errors or undesirabilities, and also by indicating how they rate the quality of the results. This feedback is incorporated in the LLMs to have the models realise better results. To this end, LLMs use large quantities of parameters in order to create links between words and combine them to form an answer. The precise quantity is unknown (estimations are between 117 million and more than 100 trillion).
At the ‘frontend’ of ChatGPT, users are dealing with something that looks like an advanced chatbot or search engine. Users enter a prompt, which is the search query, and ChatGPT subsequently generates a text. Users can interact with ChatGPT about that text. This is more advanced than a regular chatbot, because ChatGPT generates texts instead of pre-programmed answers, which is the case with chatbots known to date.
ChatGPT’s possibilities of application
ChatGPT offers multiple possibilities of application within a large variation of domains. It provides the option of automating and accelerating work of a linguistic nature, and could provide support to that end. It is important to distinguish between generating information and structuring texts or making them easy to read.
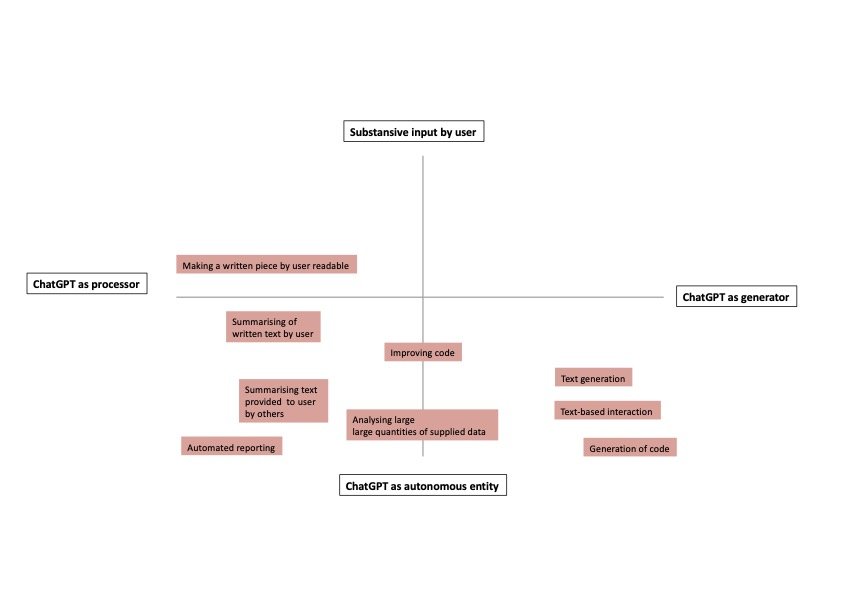
Technical limitations of LLMs and the ethical aspects thereof
LLMs have many possibilities of application, but those applications are not without limitations. In other words: LLMs can do much, but there is also a lot that they cannot do or cannot do well or well enough. Users are most exposed to the limitations of the model and the ethical aspects thereof when they have ChatGPT generate complete or partial texts (see picture above). A number of factors currently contribute to the model’s unreliability.
Not neutral
The texts generated by ChatGPT are not neutral. The model is value-based because it has been trained using many data sets that unintentionally and implicitly present certain implicit or explicit values, views of humanity and world views (bias).[iv] Moreover, the model has been adjusted by RLHF, which means that it becomes less likely that certain offensive texts (extremist, discriminatory or insulting texts) can be generated by ChatGPT (even though this can be bypassed with certain prompts).[v]
Hallucinations
The model is said to ‘hallucinate’. ChatGPT does not have a ‘model of reality’ and bases itself purely on already existing language and language sources. Whether something is true or not does not play a role in the formation of texts by ChatGPT. As a result, ChatGPT reproduces incorrect information and linguistic expressions with facts with the same amount of certainty. The risk of large-scale distribution of incorrect information is realistic when using ChatGPT.[vi]
Intransparancy
A third factor of unreliability is the intransparency of the model and its realisation. It is difficult, if not impossible, to find out how and on which basis the model has achieved its output. Moreover, for a model such as ChatGPT it is unclear which training data the model contains.[vii] The intransparency is largely a consequence of the complexity of the model and the manner in which it has been designed. There is hardly any to no insight into the conditions that the system is supposed to meet.[viii]
The model’s risks are particularly pointed out as and when it may function more as an independent entity and may generate ‘new’ texts. Risks include a wide dissemination of misinformation and disinformation, discrimination and stigmatisation. A linguistic processing operation in respect of an already existing text is less risky, but certainly not without risks, in the light of the stated limitations.
Statutory parameters
Around the world, organisations and authorities are visibly struggling with the legal implications of ChatGPT. The use of LLMs and ChatGPT in particular in all likelihood violates all kinds of statutory limits, including violations of the General Data Protection Regulation (GDPR) and copyright infringements, but also violations of human rights and health and safety regulations. The existing statutory parameters indicate that the use of ChatGPT is already problematic, which is apparent from the reactions to the super-fast developments around generative AI in various countries:
GDPR
In April 2023 the use of ChatGPT was temporarily blocked in anticipation of answers to the questions submitted by the Italian supervisory authority GPDP to OpenAI. At the same time, an investigation was launched into the potential violation of the General Data Protection Regulation (GDPR).[ix] In early June 2023, the Dutch Data Protection Authority of the Netherlands also asked OpenAI to clarify how personal data is treated when training the model.[x] On 13 June 2023 Google announced that it is postponing the European introduction of AI Chatbot Bard after criticism expressed by the Irish Data Protection Commission (DPC) about the handling of personal data, but after adjusting its privacy policy introduced Bard to the European market a month later.[xi] On 16 May 2023, OpenAI CEO Sam Altman had to testify in the American Senate about the risks of AI.[xii]
AI act
Europe has been working on legislation relating to the use of AI for some time now. In June 2023, the European Parliament agreed to the introduction of a European AI Regulation. This regulation makes a risk classification of AI systems. Prohibitions, measures or transparency requirements apply depending on the identified risks. The arrival of generative AI puts pressure on this risk-based approach.[xiii] The models are large-scale and have not been developed for one specific purpose, making the risks difficult to assess.[xiv] Recently the European Parliament decided to include additional requirements for so-called Foundation Models (which include ChatGPT). This means that transparency requirements are set for the makers of the models in terms of the protection of health and safety, the democratic legal system and the environment. Furthermore, it is requested that AI generated content be labelled as such, making the outcome traceable for users.[xv] The European AI Regulation will take effect in 2025 at the earliest.[xvi]
Calls for stricter regulation
In addition, many are currently calling for even stricter regulation and policy with respect to AI. In March 2023, the British government published an AI white paper, calling on supervisory authorities to make better rules.[xvii] In June 2023, the former Dutch Politician Kees Verhoeven, launched a similar initiative by means of a petition calling on politicians to speed up the European directives and set up a national action plan.[xviii] In a report published by The Netherlands Scientific Council for Government Policy early this year, recommendations are made to authorities for the better embedding of AI. What is striking is that the emphasis is mostly on developing skills and knowledge about AI, and proper regulation in order to avoid losing control of the technology.[xix]From an ethical perspective, the question is how the user wants to relate to these parameters, these developments and this context.
Copyright infringements will be discussed below under arts & culture.

The ethical aspects of using ChatGPT
Various ethical aspects have already been discussed above. We are now zooming in on the ethical aspects of the use of ChatGPT in several domains.
The individual user
When using ChatGPT as an individual user, this means something for the way the user operates. The user needs certain skills to make the most out of the model, think of learning how to use an effective prompt, but also how to evaluate the output of the model. One could say the user would also be in need of techno moral skills so the user can make a deliberate choice on whether or not to use the model in a responsible way. At the same time, while making use of ChatGPT, one might get de-skilled in other competences. There could grow a dependency on the model which might affect the user in other ways. This all depends on how ChatGPT is being used and whether or not the user is more in control or gives more autonomy to the model.
The autonomy of the user itself could be strengthened buy ChatGPT, because the user might be able to do things they weren’t able to do before, or maybe only in a slower pace. At the same time autonomy is under threat because there might be a risk that the user does not only externalises parts of its thinking and creating, but also responsibility. The user might be influenced by what ChatGPT generates and might be trusting the outcomes of the model too much (‘overreliance’).[xx]
Society and politics
The large-scale use of LLMs such as ChatGPT has a great impact on society. Public values such as justice, information, trust and autonomy may come under pressure the further such models are distributed in society. When it comes to society and politics, there are a number of matters that may be impacted by the use of ChatGPT.
First of all, ChatGPT might influence trust in the government. Society has a need for a reliable government that warrants public values.[xxi] However, the increasing flow of disinformation that can be produced easily and fast by AI and subsequently be disseminated via media and social media can have a great impact on election processes, for instance. AI generated text and images can be used to deliberately disseminate fake electoral information or to manipulate voters, with all the associated risks.[xxii] In addition, there are risks that groups within society or even society as a whole loses trust in the government if it starts making choices based on information generated by models, which may be value-based, incomplete or incorrect.[xxiii]
Secondly, power and influence are relinquished by the prompts and texts that are entered. If they contain company details, personal data or public data, these become available to the models’ developers. It could be stated that persons, companies and authorities are unintentionally or without noticing losing or relinquishing power as a result.[xxiv] Influence can also be exercised unnoticed when LLMs are used.[xxv] Values, views of humanity and ideologies may emerge in the creation of political or lobby sector generated strategy and policy texts that might not match the wider public interest and public values. The question is to what extent this potentially subtle influence is noticed.[xxvi]
Thirdly, the use of LLMs may cause a larger inequality in society, both socially and economically. AI is supposed to help improve our lives and make better choices, but this turns out to be more complicated in practice. Moreover, many people do not have the digital skills to properly use technological advances,[xxvii] creating an even wider gap between those who have sufficient financial and intellectual capital to fully use technology and those who were already running behind in that respect.
Fourthly, the large-scale use of LLMs will influence employment. Some positions may change or disappear, while other positions suddenly arise. The impact of LLMs will be visible mainly in so-called ‘highly educated white-collar’ professions, and professional groups in which automation is lurking.[xxviii] LLMs will influence jobs no matter what, and it is important to make sure that this process is steered in the right direction, and that employees, where necessary, are assisted in acquiring the right digital skills.
Finally, there is the risk of disinformation, as referred to above. The large-scale use of AI may cause a flood of fake news (also referred to as ‘infocalypse’) that causes an information crisis.[xxix] The better LLMs become in imitating natural language, the more difficult it becomes to distinguish ‘real’ information from ‘fake’ information, which may cause all types of social unrest, for example during the COVID-19 crisis.

Education
Ever since ChatGPT went live in late 2022, pupils and students have eagerly used the model to improve their homework assignments, book reports and essays or even write them from scratch. This has caused concern in the world of education, because ChatGPT generated output should be treated critically. A check of the content of the text is always necessary, because the model puts forward the most ridiculous statements as facts with the utmost self-confidence.
This large-scale use raises issues among educational staff and institutions. All of a sudden, the way in which homework and testing are set up is called into question. Following on from plagiarism detectors, ‘AI detectors’ are now released as well, but research conducted earlier this year does not present hopeful results for their reliability.[xxx] Educational institutions are struggling with the attitude that they need to adopt towards the use of LLMs; should they ban them altogether, or rather integrate them on the terms set by teachers or institutions? The smartest option seems to embrace the technology, but this might have consequences for the educational developments for pupils and students in the long term. Practising writing or academic writing, for example, draws upon skills such as critical thinking, which are also necessary to evaluate the output of models. Moreover, the use might have a negative impact on pupils and students who are already disadvantaged in education.[xxxi]
Arts and culture
Naturally, generative AI also greatly impacts arts and culture. Where models using images have impact on illustrators, designers and other artists, language models influence all art relating to the written word.
The first books written by AI are already on the market. AI tools are used to publish books through platforms such as Amazon’s Kindle Direct Publishing. There is concern about a flood of AI generated books on such platforms, whose quality is potentially low and which might result in the disappearance of writing as a professional skill.[xxxii] Moreover, Amazon has not described anywhere in the terms and conditions that it has to be clear that a book has been generated by AI, which means that anyone can pose as a creative genius.[xxxiii]
Apart from discussions about the quality and quantity of the art generated by LLMs, this constitutes infringement of copyright because sources that are publicly accessible have been used as training data without source references or permission, and original pieces of text might end up in the output.[xxxiv] The first legal proceedings have already been instituted with respect to other forms of generative AI, where attempts of developers to have the legal proceedings dismissed were decided in favour of the claimants.[xxxv] At the same time, the ownership and copyright of the text are under discussion, because it is not clear whether a text generated by a user in ChatGPT is covered by this protection. It could be argued that the output is created by the creative and ‘original’ choices upon the input of the prompt by a user. [xxxvi]OpenAI states that copyright does not always apply because a similar prompt by another user may lead to a comparable output.[xxxvii]
Privacy and security
An aforementioned problem of LLMs are the privacy and security risks. The prompts that people enter to generate output largely end up in the model as training data.[xxxviii] Moreover, data and sensitive data end up in the model as training data unasked and without permission through public sources. People do not have any say or control over this.[xxxix] There is therefore always a risk that data or sensitive data end up in the output of another prompt request later on.
Moreover, LLMs are sensitive to prompt leaks and prompt injections. ‘Prompt leaks’ means that the input of users is leaked, by a hack for example. ‘Prompt injections’ means that the prompt is injected with additional or other information, as a result of which the model executes the prompt in a different manner. This means that information can be diverted as a result.[xl]
Another problem is that AI applications are shooting up like mushrooms, for example in the form of browser extensions; from writing support to transcribing app to shopping assistants and price checkers: you name it and there is an AI-powered tool available in your browser’s web stores. Even though many of these extensions do what they promise, a lot of them are simply malware stealing your data.[xli] Moreover, the browser extensions are confronted with the same risks listed above, such as information ending up in training data, potential data breaches at companies or copyright infringements.

Hidden costs of LLMs
There are also ethical aspects that do not directly play a role in the use of LLMs, and ChatGPT in particular, that are involved in the use and existence of these tools. Various ethical aspects that may be viewed as ‘costs’ to society (such as privacy and security) have already been listed in previous chapters. An explanation of further externalities is given below.
Climate impact
The training and use of ChatGPT impacts the climate because of huge CO2 emissions and large quantities of water needed to cool the servers of data centres.[xlii] The electricity grid, which is already under great pressure, is heavily relied on, and the electricity that is used usually is not sustainably generated electricity. The production of the hardware needed for the servers involves pollution.[xliii] Moreover, these servers take up a lot of space, which means that other ‘functions’, such as historical sites or nature, have to make place.[xliv] This adverse impact on the environment is not immediately visible at the locations where the models are used, and is particularly passed on to more vulnerable communities (climate injustice).[xlv]
Economic and social inequalities
LLMs are currently created by using and reinforcing existing economic and social inequalities. Clickworkers in ‘low-wage countries’ are used to further train the model (RLHF), but many clickworkers are also active in Europe and America. All over the world, they work for extremely low rates. This work is mentally very demanding and sometimes even traumatising.[xlvi]
In addition to the use of low-wage clickworkers, the Rathenau Institute already warned that citizens (and even civil servants) are training Silicon Valley’s models free of charge. According to Rathenau, it is important to keep in mind to what end AI is being developed and who benefits.[xlvii] Developers are now using the input of users free of charge to refine the systems and in doing so increase their market position and capital.[xlviii]
Power shifting
The massive use and training of the models might shift power towards big tech because with the training of the model, there’ll be a potential power shift as is described in the section society & politics.
And now?
This blogpost is posted in a moment in time when lot’s of things are uncertain. There is a continuous stream of research and articles on this topic. We might update this post in the near future. For now, we hope the reader has an overview of the urgent ethical aspects concerning LLMs like chatGPT.
This blogpost is mainly based on our research on the ethical aspects of ChatGPT in the context of the Dutch Provinces. This research led to an advice by the Ethical Committee of the Interprovincial Cooperation (IPO) on the uses of ChatGPT within the Dutch Provinces (July 5th 2023). Translational help (Dutch to English) by Astrid Amels from 040taaldiensten.
[i] https://blogs.microsoft.com/blog/2023/03/16/introducing-microsoft-365-copilot-your-copilot-for-work/
[ii] https://arxiv.org/abs/2201.08239
[iii] https://www.wired.com/story/how-chatgpt-works-large-language-model/
[iv] https://bioethicstoday.org/blog/chatgpt-ethics-temptations-of-progress/
https://www.sciencedirect.com/science/article/pii/S266734522300024X#sec7
[v] https://www.universiteitleiden.nl/nieuws/2023/03/chatgpt-heeft-linkse-voorkeur-bij-stemwijzer
[vi] https://www.nytimes.com/2023/05/01/business/ai-chatbots-hallucination.html
https://www.bloomberg.com/news/newsletters/2023-04-03/chatgpt-bing-and-bard-don-t-hallucinate-they-fabricate
[vii] https://towardsdatascience.com/why-we-will-never-open-deep-learnings-black-box-4c27cd335118
[viii] https://arxiv.org/pdf/2202.09292.pdf, pg. 11-12
[ix] https://www.bbc.com/news/technology-65139406
[x] https://autoriteitpersoonsgegevens.nl/actueel/ap-vraagt-om-opheldering-over-chatgpt
[xi] 1) https://nos.nl/artikel/2478817-google-stelt-introductie-ai-chatbot-in-europese-unie-uit-na-kritiek-ierse-privacywaakhond 2) https://nos.nl/artikel/2482616-googles-antwoord-op-chatgpt-nu-ook-in-nederland
[xii] https://edition.cnn.com/2023/05/16/tech/sam-altman-openai-congress/index.html
[xiii] https://crfm.stanford.edu/2023/06/15/eu-ai-act.html
[xiv] https://policyreview.info/essay/chatgpt-and-ai-act
[xv] 1) https://www.europarl.europa.eu/news/en/press-room/20230505IPR84904/ai-act-a-step-closer-to-the-first-rules-on-artificial-intelligence 2)https://www.europarl.europa.eu/news/en/press-room/20230505IPR84904/ai-act-a-step-closer-to-the-first-rules-on-artificial-intelligence
[xvi] https://artificialintelligenceact.eu/standard-setting/
[xvii] https://www.cnbc.com/2023/03/29/with-chatgpt-hype-swirling-uk-government-urges-regulators-to-come-up-with-rules-for-ai.html
[xix] https://english.wrr.nl/topics/artificial-intelligence/documents/reports/2023/01/31/mission-ai.-the-new-system-technology
[xx] 1) https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3452052 2) https://hai.stanford.edu/news/ai-overreliance-problem-are-explanaCons-soluCon
[xxi] https://www.rathenau.nl/nl/digitalisering/publieke-waarden-en-digitalisering
[xxii] https://www.pbs.org/newshour/politics/ai-generated-disinformation-poses-threat-of-misleading-voters-in-2024-election
[xxiii] https://direct.mit.edu/daed/article/151/2/309/110609/Distrust-of-Artificial-Intelligence-Sources-amp, https://www.rathenau.nl/nl/digitalisering/ai-bedrijven-gebruiken-burgers-als-proefkonijnen
[xxiv] https://www.rathenau.nl/nl/digitalisering/ai-bedrijven-gebruiken-burgers-als-proefkonijnen
[xxv] https://arxiv.org/pdf/2304.08968.pdf
[xxvi] https://www.technologyreview.com/2023/03/14/1069717/how-ai-could-write-our-laws/
[xxvii] https://www.utwente.nl/en/news/2023/5/673501/how-digitalisation-is-exacerbating-social-inequality#intelligent-devices-but-not-the-right-decisions
[xxviii] https://www.washingtonpost.com/opinions/interactive/2023/ai-artificial-intelligence-jobs-impact-research/
[xxix] https://www.wired.co.uk/article/virtual-briefing-deepfakes-nina-schick
[xxx] https://theconversation.com/we-pitted-chatgpt-against-tools-for-detecting-ai-written-text-and-the-results-are-troubling-199774, https://communities.surf.nl/en/ai-in-education/article/ai-generated-text-detectors-do-they-work
[xxxi] https://www.nature.com/articles/s42256-023-00644-2
[xxxii] https://www.reuters.com/technology/chatgpt-launches-boom-ai-written-e-books-amazon-2023-02-21/
[xxxiii] https://kdp.amazon.com/en_US/help/topic/G200672390
[xxxiv] https://www.groene.nl/artikel/dat-zijn-toch-gewoon-al-onze-artikelen
[xxxv] https://www.theverge.com/2022/11/8/23446821/microsoft-openai-github-copilot-class-action-lawsuit-ai-copyright-violation-training-data, https://www.theverge.com/2023/1/16/23557098/generative-ai-art-copyright-legal-lawsuit-stable-diffusion-midjourney-deviantart, https://theconversation.com/chatgpt-is-a-data-privacy-nightmare-if-youve-ever-posted-online-you-ought-to-be-concerned-199283, https://decorrespondent.nl/14529/kunstmatige-intelligentie-is-vooruitgang-beloven-ai-bedrijven-maar-voor-wie/1858845b-2099-022b-3610-f403316d2e43
[xxxvi] https://openai.com/policies/terms-of-use, https://intellectual-property-helpdesk.ec.europa.eu/news-events/news/intellectual-property-chatgpt-2023-02-20_en
[xxxvii] https://openai.com/policies/terms-of-use
[xxxviii] https://www.forbes.com/sites/lanceeliot/2023/01/27/generative-ai-chatgpt-can-disturbingly-gobble-up-your-private-and-confidential-data-forewarns-ai-ethics-and-ai-law/?sh=5d7dd7ce7fdb
[xxxix] https://www.wired.com/story/italy-ban-chatgpt-privacy-gdpr/, https://journals.sagepub.com/doi/10.1177/0263775816633195, https://waxy.org/2022/09/ai-data-laundering-how-academic-and-nonprofit-researchers-shield-tech-companies-from-accountability/
[xl] https://simonwillison.net/2023/Apr/14/worst-that-can-happen/
[xli] https://www.kolide.com/blog/ai-browser-extensions-are-a-security-nightmare
[xlii] 1) https://hai.stanford.edu/news/2023-state-ai-14-charts, 2) https://www.wired.com/story/the-generative-ai-search-race-has-a-dirty-secret/, 3) https://arxiv.org/pdf/2304.03271.pdf,4) https://www.nbcnews.com/tech/internet/drought-stricken-communities-push-back-against-data-centers-n1271344
[xliii] https://left.eu/content/uploads/2023/02/ENVI-Study-Data-centers-web.pdf
[xliv] 1) https://www.npca.org/advocacy/102-keep-massive-industrial-data-centers-away-from-our-national-parks, 2) https://www.theguardian.com/us-news/2023/jun/05/virginia-historic-preservation-data-center-development
[xlv] https://www.nbcnews.com/tech/internet/drought-stricken-communities-push-back-against-data-centers-n1271344
[xlvi] 1) https://time.com/6247678/openai-chatgpt-kenya-workers/, 2) https://www.linkedin.com/pulse/he-helped-train-chatgpt-traumatized-him-alex-kantrowitz%3FtrackingId=1xpu7c1JQ121dbBuawEYNQ%253D%253D/?trackingId=1xpu7c1JQ121dbBuawEYNQ%3D%3D, 3) https://www.volkskrant.nl/nieuws-achtergrond/eindeloos-stoplichten-taggen-en-praten-met-alexa-wie-zijn-de-mensen-achter-ai~bd971b009/, 4) https://www.vpro.nl/programmas/tegenlicht/kijk/afleveringen/2023-2024/de-prijs-van-ai.html
[xlvii] https://www.rathenau.nl/nl/digitalisering/ai-bedrijven-gebruiken-burgers-als-proefkonijnen
[xlviii] 1) https://www.technologyreview.com/2022/04/19/1049378/ai-inequality-problem/ 2) https://theconversation.com/ai-will-increase-inequality-and-raise-tough-questions-about-humanity-economists-warn-203056